


Optimizing Large Dataset Processing with Parquet: The Best Storage Format for Efficient AutoML Workflows

Parquet is a columnar storage format optimized for efficient data storage, access, and processing in big data environments. Unlike traditional row-based storage formats such as CSV, Parquet is designed specifically for read-heavy, high-performance scenarios, which are common in data analysis and machine learning workflows. Its structure and compression methods make it ideal for handling large datasets, particularly in AutoML workflows where data retrieval and storage are frequent operations.
Why Parquet is Ideal for Large Datasets
Parquet’s efficiency stems from its columnar format, which enables selective loading and compression of specific columns, significantly reducing data access time and memory usage. These features are advantageous for AutoML workflows and big data processing, as they allow users to read only the necessary portions of the data without loading the entire dataset into memory.
Some notable benefits of Parquet include:
Columnar Storage: Only the required columns are loaded, minimizing memory usage.
Compression and Encoding: Reduced storage requirements and faster read/write speeds.
Compatibility: Parquet is compatible with various big data platforms, making it easy to integrate into existing data infrastructures.
What is Columnar Storage, and How Does It Work?
In traditional row-based storage formats, like CSV, data is stored by rows, meaning that each row’s columns are stored together. Here’s an example of a row-based storage structure:

Whenever we need to access only the “Age” or “City” column, the CSV format requires reading the entire row and then extracting the relevant column, leading to inefficient memory usage when processing large datasets.
Parquet, on the other hand, uses a columnar format where each column’s data is stored together. Instead of reading entire rows, Parquet allows us to load only the required columns into memory, significantly improving performance. Parquet stores the example table as follows:
ID:
1, 2, 3Name:
Alice, Bob, CharlieAge:
25, 30, 28City:
New York, Chicago, Seattle
With this structure, Parquet can load only the “Age” column if needed, without accessing unnecessary data. This columnar storage design makes Parquet highly efficient for large datasets and big data applications, especially in AutoML workflows where specific features or columns are frequently accessed or analyzed.
How Parquet Files Operate: Partitioning and Compression
Partitioning
Parquet allows data partitioning, which is essentially organizing data based on one or more specific columns. This enables efficient, targeted read operations. For example, consider a large stock trading dataset containing several years of records. Partitioning this data by year makes it possible to load only the relevant years without reading the entire dataset. Partitioned data would look like this:
dataset.parquet/
├── year=2022/
│ ├── part-0001.parquet
│ └── part-0002.parquet
├── year=2023/
│ ├── part-0001.parquet
│ └── part-0002.parquet
If we need only 2022 data, we can directly load the year=2022 partition, which improves read speed and reduces memory usage by not loading other years.
Compression
Parquet also supports various compression algorithms, such as Snappy and GZIP, which reduces file sizes and read times. In columnar storage, data within a column is often of similar types, making compression particularly effective. For example, in the “Age” column where values are small integers, Parquet’s compression encodes these values efficiently, further reducing the file size. This is advantageous for large-scale data storage, where reduced file sizes translate into lower storage costs and faster read/write times.
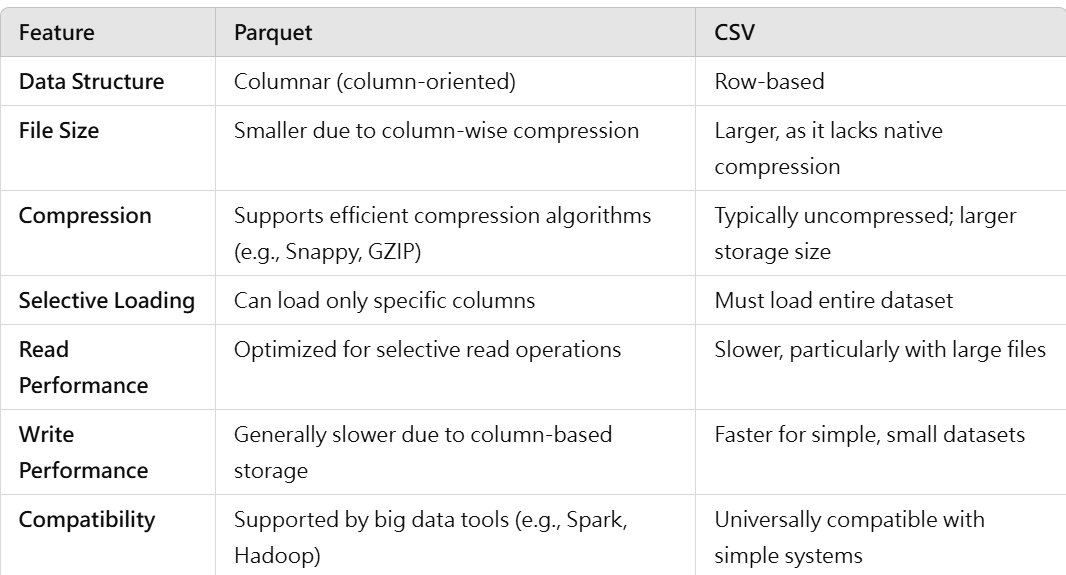
The table below provides a detailed comparison between Parquet and CSV formats, illustrating how Parquet offers more efficient data handling capabilities for large datasets.
Advantages of Parquet Format for AutoML Workflows
Optimized Storage and Speed: Parquet’s columnar structure is ideal for scenarios requiring fast, repeated data access, as it only loads the columns needed for a given task. In AutoML, where data is frequently read, this feature dramatically reduces memory and computational overhead.
Cost-Efficiency: Compression reduces storage costs, which is particularly beneficial for large-scale datasets used in cloud environments.
Scalability and Partitioning: Parquet supports data partitioning based on specific columns, allowing AutoML workflows to load only relevant data segments. For instance, time-based partitioning in stock datasets enables loading only specific time frames for training, making large datasets manageable and efficient.